728x90
728x90
pandas
구조화된 데이터 효과적으로 처리
numpy의 array가 보강된 형태 , data 와 index 가짐
Series
1차원 다룸, Series 는 값(values)을 ndarray형태로 가짐.
import pandas as pd
data = pd.Series([1,2,3,4])
print(data)
'''
0 1
1 2
2 3
3 4
'''
print(type(data)) # <class 'pandas.core.series.Series'>
print(data.values) # [1 2 3 4]
print(type(data.values)) # <class 'numpy.ndarray'>
dtype인자로 데이터 타입 지정가능
data = pd.Series([1,2,3,4],dtype="float")
print(data.dtype) #float64
인덱스를 지정가능 , 인덱스로 접근 가능
data = pd.Series([1,2,3,4], index =['a','b',',c','d'])
data['c']=5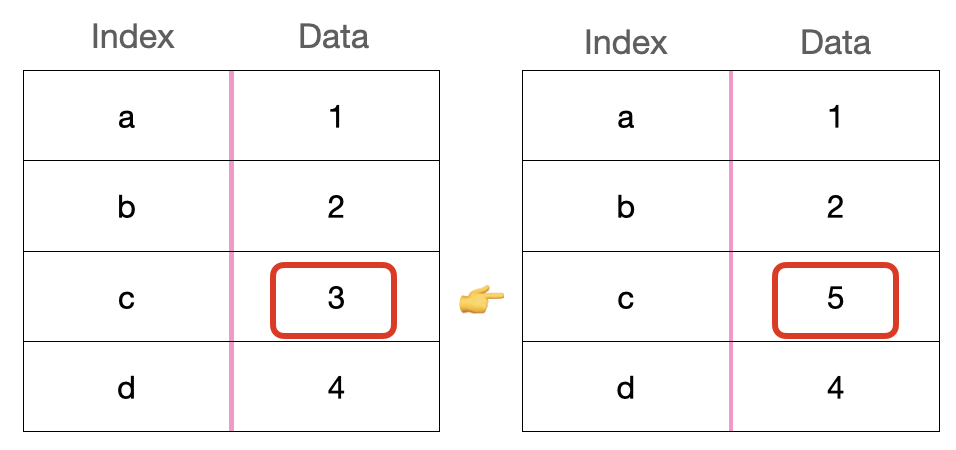
Dictionary를 활용해서 Series 생성 가능
import pandas as pd
pop_dict={
'name':'uni',
'age':'24'
}
data = pd.Series(pop_dict)
print(data)
'''
name uni
age 24
dtype: object
'''
DataFrame
2차원 다룸, Dictionary로 DataFrame 생성 가능
import pandas as pd
pop_dict={
'id':['a1','a2'],
'name':['uni','yunhui'],
'age':['24','7']
}
data = pd.DataFrame(pop_dict)
data = data.set_index('id')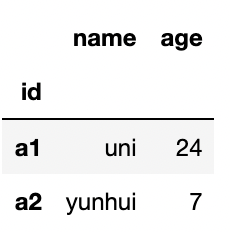
dataframe 속성확인
print(data.shape) # (2,2)
print(data.size) # 4
print(data.ndim) # 2
print(data.index) # Index(['a1', 'a2'], dtype='object', name='id')
print(data.values)
'''
[['uni' '24']
['yunhui' '7']]
'''
dataframe의 index와 column에 이름 지정
data.index.name = "person_id"
data.columns.name="Info"
print(data.index) # Index(['a1', 'a2'], dtype='object', name='person_id')
print(data.columns) # Index(['name', 'age'], dtype='object', name='Info')
dataframe 저장 및 불러오기 가능
data.to_csv("./person.csv") # csv파일로 저장
data=pd.read_csv("./person.csv") # csv파일을 dataframe으로 불러오기
여러개의 시리즈 데이터를 합쳐 하나의 dataframe으로 만들기
dict1 = {
'apple': 12,
'banana': 13,
'cherry': 14,
'lemon': 15
}
stock = pd.Series(dict1) # series 1
dict2 = {
'apple': 1111,
'banana': 2222,
'cherry': 3333,
'lemon': 4444
}
price = pd.Series(dict2) # series 2
fruit=pd.DataFrame({
'stock(개)':stock,
'price(원)':price
}) # dictionary의 value 값을 series들로 넣고, 그것을 dataframe 형태로 바꾸면 됨!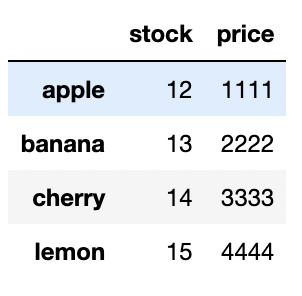
데이터 선택 - Indexing / Slicing
.loc : 명시적인 인덱스를 참조하는 인덱싱/슬라이싱 (a:b 이면 b 도 포함함!)
.iloc : 파이썬 스타일의 정수 인덱스 인덱싱/슬라이싱 (a:b 이면 b-1까지 포함!)


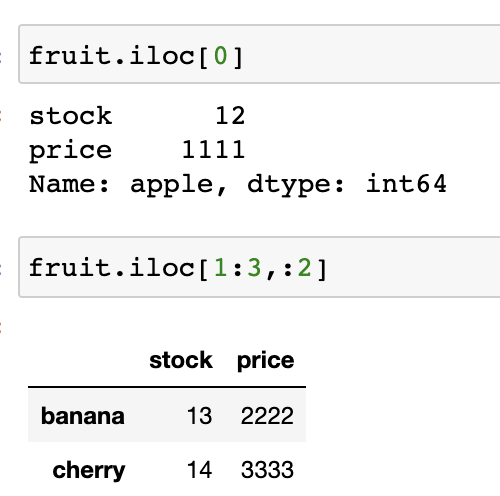
컬럼명으로 DataFrame에서 데이터 선택 가능


Masking 연산이나 query함수으로 조건에 맞는 DataFrame 행 추출 가능

Series도 numpy array처럼 연산자 활용 가능
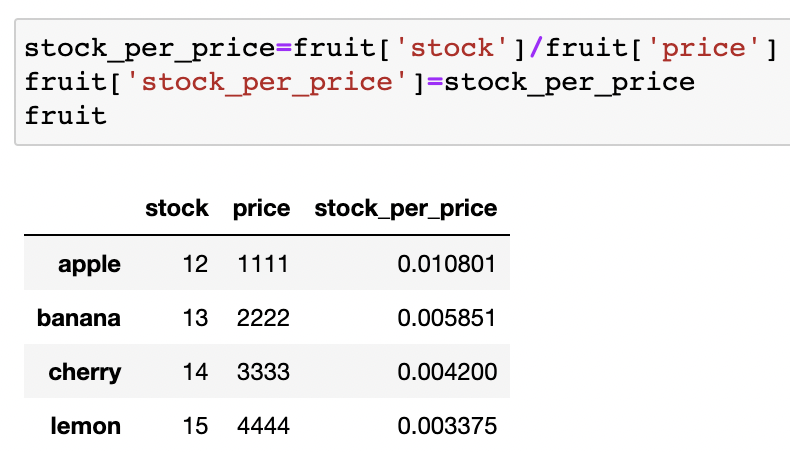
데이터 변경 - 데이터 추가/수정

NaN값으로 초기화 한 새로운 컬럼 추가

DafaFrame에서 컬럼 삭제 후 원본 변경

728x90
728x90
'ML & DL > 데이터 분석' 카테고리의 다른 글
| [pandas] Dataframe 행 위,아래로 옮기기 : shift() (0) | 2022.06.02 |
|---|---|
| [python] Numpy 기초 (0) | 2021.09.28 |
| [python] 웹페이지 크롤링 기초 (0) | 2021.09.28 |

댓글